
C语言函数、指针、宏以及头文件的认识
对C语言更高阶的认识,从野生到正统,从杂牌军到正规军。
1、printf函数的理解
printf函数的原型:*int printf(const charformat,...);**
format:字符串,
...:代表输入的参数是变参,类型通过format里面来指定。
返回值:代表输出的字符个数。
返回值示例代码:
int a=123;
printf("%d\n",printf("%d\n",printf("%d\n",a)));
变参的处理:会用到一组函数来进行变参的获取,主要有以下几种类型:
va_list 类型:变参的结构类型,首先定义变量,其是指向参数的指针;
va_start():初始化该变量,即获取变参的地址
va_end():销毁变参,结束变参数据的获取。
va_arg():获取变参数据,如果是多个变参,可以通过多次调用来依次回去参数数据;
示例代码如下:
int demo(char*msg,...)
{
va_list argp;
int arg_num=0;
char *para;
va_start(argp,msg);
while(1)
{
para = va_arg(argp,char*);
if(strcmp(para," ") == 0) //为了退出而写
break;
printf("Para #%d is %s\n",arg_num,para);
arg_num++;
}
va_end(argp);
return 0;
}
demo("msg","this","is","a","demo!"," ");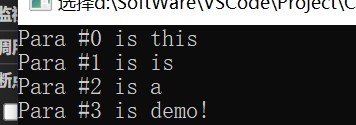
标准库中的printf函数理解:
格式:%[flags][width][.precision][length] spcification
- flags:
-:左对齐,默认识右对齐
+:强制数据带±号
(space):不足空格补齐
‘#’:与十六进制联合使用,显示0x,0X
0:不足位数补0,而不是部空格 - widths:
(number):number指示显示的位宽占多少个字符,
(*):表示位数可以通过参数指定,是变参,而上面的是固定参数 - precision:
(.number):控制小数点精度位数,number指示位数 - length:不是指具体数字
h:short Int
hh:short char
d:int
l:long int
ll:long long int
u/o/x/x :(unsigned 十进制、八进制、十六进制)
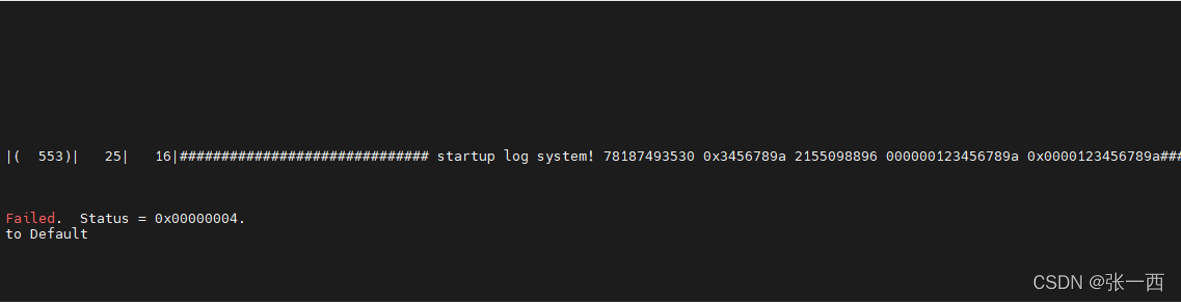
示例代码:u64 temp_data = 0x123456789a; printf("####### startup log system! %lld %#x %lld %p %#p ######",temp_data,temp_data,&temp_data,temp_data,temp_data );
结果如下图所示:
2、指针分配地址
指针需要知道几个概念:指针指向、指针内容、指针地址
指针指向:就是指针指向的一块内存。
指针内容:是指的地址里面的值。
指针的地址:指的是指针本身的地址,指针指向的也是一个地址,所以这边有点绕。
void myGetMemory(char* p)
{
p = (char*)malloc(100);
}
int main()
{
char *str=NULL;
myGetMemory(str);
strcpy(str,"hello world");
printf("%s",str);
return 0;
}上述程序的问题,就是指针的用法错误,
分析一下问题:
- 第一步 p-> str,所以p的值和str的值均为空,因为这是参数传值,会有两个变量。
- 下一步 指针p指向分配的空间,但是str并没有分配空间,
- 再一下内存拷贝会出错(段错误)。
这里错误的地方在于:本身想修改str的指向,但是没有用对方法。
- 正确修改指针的指向应该是用二级指针,因为二级指针指向是一级指针的地址,
- 那么二级指针内容即是一级指针的指向,
- 通过这种方法可以修改一级指针的指向,就可以分配到空间。
具体实现如下:
void myGetMemory(char** p)
{
(*p) = (char*)malloc(100);
}
int main()
{
char *str=NULL;
myGetMemory(&str);
strcpy(str,"hello world");
printf("%s",str);
return 0;
}还有种方法也可以,
- 将二级地址强转成整形,
- 然后传递进来,
- 再强转成指针,
- 最后其指针内容就是str指向的空间,给其空间赋值,后面就可以拷贝。
void myGetMemory(int p) { *(int *)(p) = (int)(char*)malloc(100); } int main() { char *str=NULL; myGetMemory((int)&str); strcpy(str,"hello world"); printf("%s",str); return 0; }
3、宏的使用
‘#define’ 宏定义常量、函数,高阶用法:
- 实现“重载”,动态过滤提供效率
#if (VERSION == 1)
MY_PRINT(a) my_one_log_print(a)
#elif (VERSION == 2)
MY_PRINT(a) you_own_log_print(a)
#endif- 多内容替换,假如说宏内容中有需要通过if条件来进行是否选择执行,可以选用这种方法。
#if (VERSION == 1)
#define MY_PRINT(a) \
do \
{\
if(LEVEL == DEBUG)\
{\
my_own_log_print(a);\
}\
}while(0)
#elif(VERSION == 2)
#define MY_PRINT(a,b) \
do \
{\
if(LEVEL == DEBUG)\
{\
my_own_log_print(a,b);\
}\
}while(0)
#endif- 名字空间,担心宏与其他宏进行重复,但是又不想宏名字太长,可以选用这种方法,
void my_own_log_print(u8 _level,fmt,...);
#define LOG_DEBUG 0
#define LOG_INFO 1
#define LOG_WARN 2
#define LOG_CRIT 3
#define MY_PRINT(_level,_fmt,...) my_own_log_print(LOG_##_level,_fmt,##_VA_ARGS__)
int main()
{
my_own_log_print(INFO,"this is my log!\n");
return 0;
}- 编译器自带的宏,无需自己定义,可以直接使用。
__FILE__:显示当前文件路径及名称
__FUNCTION__:当前所在函数
__LINE__:所在行号
__DATE__:当前日前
__TIME__:当前时间
-
几个符号常见的用法 '#,##,VA_ARGS,##VA_ARGS'
-
[x] #:将后面紧跟的符号转化为字符串
#define PRINT_VAL(n, val) printf("%s = %d\n", #n, val)
int x1 = 3;
PRINT_VAL(x1, x1);
- [x] ##:将##左右两边的符号连接在一起变成一个符号
#define VAR_NAME(n) x##n
int VAR_NAME(0) = 0; //定义整型变量 x0=0;
- [x] __VA_ARGS__:表示该部分允许输入可变参数,必须有参数才行
#define LOGD(format, ...) printf("debug: " format, __VA_ARGS__) - [x] ##__VA_ARGS:支持可变参数的输入或者无参数输入(参考上面变参宏替换)
#define LOGD(format, …) printf("debug: " format, ##VA_ARGS__)-
几个预编译的符号认识
-
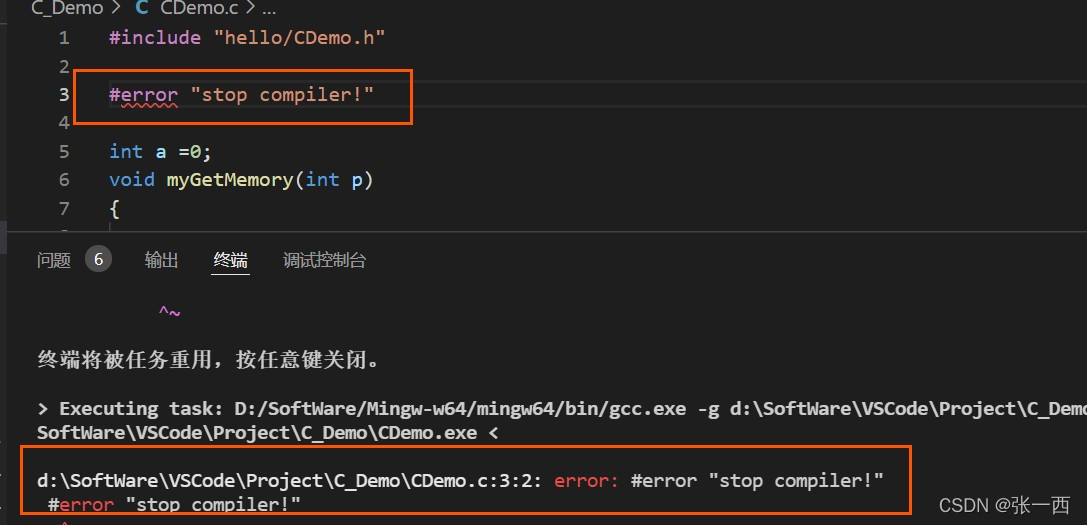
[x] #error “msg”
如果执行到该行,则停止编译,并打印msg字符串,字符串可以任意定义。常用来做编译检查,如果代码被修改,则会编译报错;
- [x] #ifdef、#ifndef、#else、#endif /#if defined、#if !defined (是否存在定义)
/*只是判断其宏是否存在定义 对于宏的值并不关心*/
/* 静态的if语言判断 静态是指:编译器预处理时 */
#ifdef ENABLE_PRINT
/* 定义了该宏,不管其定义为何值 都成立,预编译时 则将该宏替换掉 */
#define MY_PRINT(_level,_fmt,...) my_own_log_print(LOG_##_level,_fmt,##_VA_ARGS__)
#else
#define MY_PRINT(_level,_fmt,...)
#endif
void msg_process()
{
/*....*/
MY_PRINT(INFO,"this is msg process!\n");
/*...*/
}
#if defined <==> #ifdef /*这两种时等价的*/
/*此外 其还可以用多种宏的组合判断*/
#define A
#define B
#if defined A && defined B
#define C 100
#else
#define C 10
#endif
/**C=100*/
#define A
#define B
#if defined A && !defined B
#define C 100
#else
#define C 10
#endif
/**C=10*/- [x] #if、#elif、(关心宏的定义以及宏的值)
/*关心宏的定义以及宏的值*/
#define A 10
#if A==10
#define C 100
#elif
#define C 10
#endif
/**C=100*/4、C/C++对重载的支持
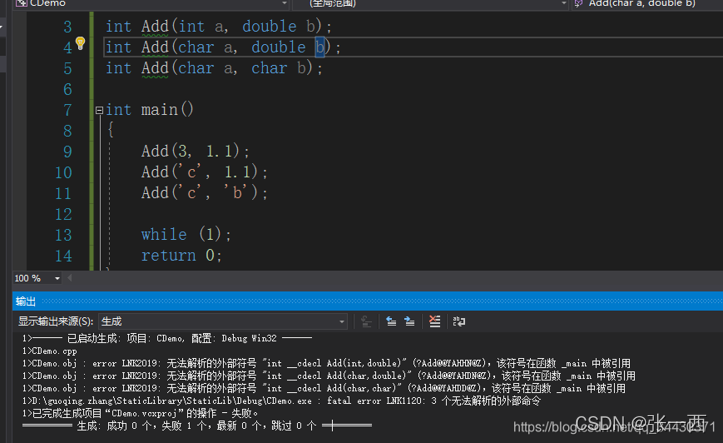
C语言不支持重载,C++支持重载
-
C语言是因为函数名即是函数地址,如果函数名一样,则地址一样,则调用时无法区分,

-
C++是因为编译器会对函数名进行修饰,按照参数的个数、顺序等,所以即使重载,最后编译器认识的函数名均不同,则分配了不同的地址,所以支持重载。
-
C如果调用C++的库,则会用出现找不到函数名的情况,所以这个时候用到了“extern C”,将其按照C语言的方法进行编译,则函数名不会进行修饰,具体参考博客:extern C :静态库与动态库
5、头文件的包含
- 头文件的认识:
- 只放接口,其他(内部函数、依赖、不相关宏、结构体 放在c文件中,不要暴露出来,减少接口数量)
- 包含头文件在用到的文件中包含,不用到的不包含,减少依赖,减少编译时间
比如:三个文件A、B、C。其.c文件包含其.h文件,有依赖关系。
- A依赖于B,如果A.h包含了B.h,则A.c中也有B.h,可以正常编译
- 此时C依赖于A,则C.h包含A.h,
- 如果B.h发生变化,则重新编译时,ABC的.c文件都需要重新编译,但是C本身与B并没有关系,但是也重新编译,岂不是浪费时间。
- 如果A.c包含B.h,那么重新编译时,则只需要编译A与B,则C无需编译。
前者包含关系:
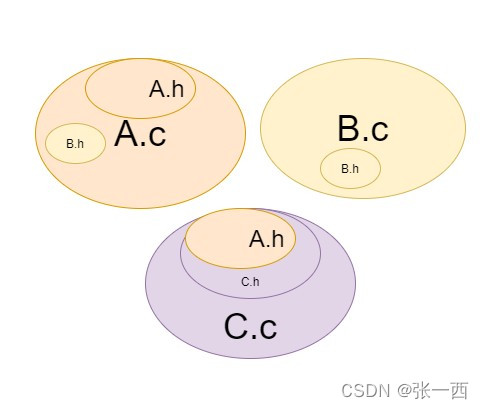
后者包含关系:
- 函数的认识:
- 变参(… ##__VA_ARGS__) va_list,
- 内部函数static修饰,接口放头文件
- 入参加const,不想被改变的返回值加const
- 简单高频次的函数声明为内联函数
- 注意层次关系,一般下层不调上层函数
版权声明:
作者:ZhangYixi
链接:http://zyixi.xyz/c%e8%af%ad%e8%a8%80%e5%87%bd%e6%95%b0%e3%80%81%e6%8c%87%e9%92%88%e3%80%81%e5%ae%8f%e4%bb%a5%e5%8f%8a%e5%a4%b4%e6%96%87%e4%bb%b6%e7%9a%84%e8%ae%a4%e8%af%86/
来源:一西站点
文章版权归作者所有,未经允许请勿转载。



共有 0 条评论