
ARM学习(20)自旋锁的理解与实现
笔者今天来学习介绍一下自旋锁(多core下的互斥访问)。
1、自旋锁的认识
学过嵌入式的,肯定会用过RTOS,嵌入式操作系统,那么肯定会遇到临界区这样的一个概念,老师或者课程资料或者网上资料都说,访问临界区需要加锁才可以,不然会出现各种各样的奇怪问题。
再比如RTOS中,会提供任务创建功能,每个任务是一个线程,多个线程访问同一个资源,比如队列,会使用互斥量(二值信号量),如果获取不到互斥量,则会进行任务切换(下图线程1),等待就绪的其他任务执行(线程2),其他任务互斥量释放之后,本任务会继续执行。
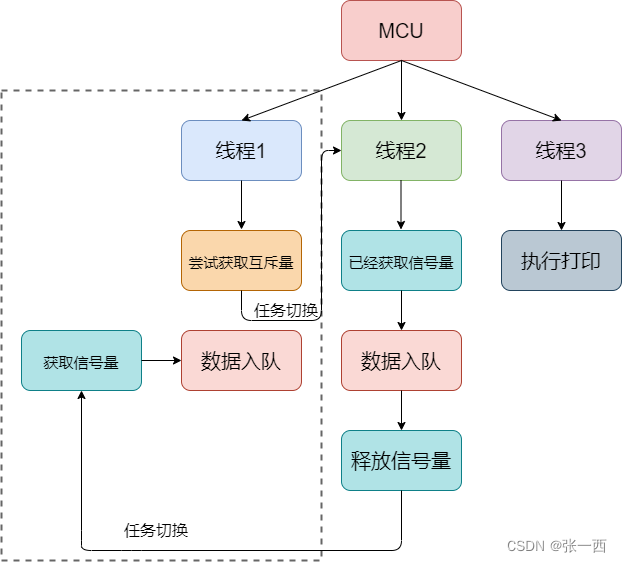
本文中的自旋锁常用于多核当中的共享资源访问,如果其中一个core拿到锁 对共享资源进行访问,那么另外的core需要等待,直到该core释放锁,就类似于一直需要自旋判断等待,如下图中core0,一直循环判断等待。

如果上述第1,2个例子是MCU是单核的,那么临界区是核内竞争,比如中断程序和主程序竞争(如果中断内允许做这个事情),一个实际的例子就是,中断程序内接收外设数据,并且标志位置1,主程序内处理数据,并置0,这样就会存在同时操作标志位的情况。
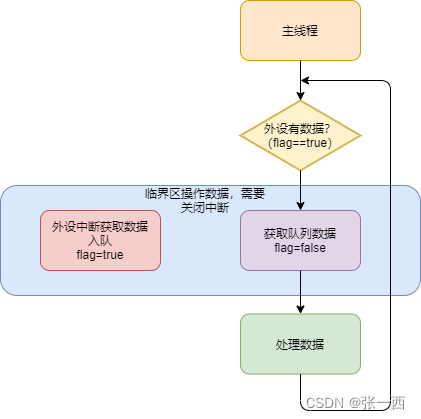
如果是多核处理器,任务中不仅有核内竞争,核间也有竞争,关中断这个操作只能解决核内竞争的问题,核间的竞争无法解决(这是实实在在两个硬件的核在运行(微观上同时运行),在竞争)。
因此我们要引入自旋锁来解决多核竞争的问题,只要有一个核拿到自旋锁,其他核就就得自转等着,等待其释放。接着我们来看一下自旋锁的实现。
自旋锁的优缺点:
- 缺点就是:没有充分利用其他核的性能,因为其他核一直在等待,没有做事,直到该核释放锁,
- 优点就是:少了任务切换带来的开销,
2、ARM下自旋锁的实现
2.1、汇编指令实现
利用原子指令来实现,原子指令这是:硬件上执行起来不可再切分的指令。
typedef struct spin_lock_struct
{
u32 lock;
}spin_lock_t;
/* void spin_lock_acquire(spin_lock_t *lock); */
spin_lock_acquire:
retry_load:
/* load the value of spin lock memory */
LDXR W1,[X0,#0]
CMP W1,#1
BEQ retry_load
/*try to write */
MOV W2,#1
SRXR W3,W2,[X0,#0]
CBNZ W3,retry_load /*check write complete?*/
/*wait write complete*/
DMB SY
RET
/* void spin_lock_release(spin_lock_t *lock); */
spin_lock_release:
MOV W1,#0
STR W1,[X0,#0]
DMB SY
RET如果支持可嵌套的锁,那需要再加一个变量去存储嵌套次数,即当前核可以多次调用同一把锁。
typedef struct spin_lock_struct
{
u32 lock;
u32 core_id;
u32 count;
}spin_lock_t;
/* void spin_lock_acquire(spin_lock_t *lock,u8 core_id); */
spin_lock_acquire:
retry_load:
/* load the value of spin lock memory */
LDXR W2,[X0,#0]
CMP W2,#1
BEQ owned
/*try to write */
MOV W3,#1
SRXR W4,W3,[X0,#0]
CBNZ W4,retry_load /*check write complete?*/
/*check the current core id have the spin lock*/
owned:
LDR W5, [X0,#4]
CMP W5,W1
BEQ self_owned
B retry_load
self_owned:
LDR W6, [X0,#8]
ADD W6,W6,#1
STR W6, [X0,#8]
/*wait write complete*/
DMB SY
RET
/* void spin_lock_release(spin_lock_t *lock,u8 core_id); */
spin_lock_release:
/* check currenr core_id is right?*/
LDR W2,[X0,#8]
CMP W1,W2
BNEQ err1
/* check count is > 1 */
LDR W3,[X0,#4]
CMP W3,#0
BEQ err1
/* count-=1 and check is the last spin lock*/
SUB W3,W3,#1
STR W3,[X0,#4]
CMP W3,#0
BEQ release
RET
/* release the core id and lock memory value*/
release:
MOV W2,#-1
STR W2,[X0,#8]
MOV W4,#0
STR W4,[X0,#0]
DMB SY
RET
err1:
B err12.2、硬件互斥实现
bool_t lock_acquire(u8 lock_index,boot_t is_wait)
{
while(*(volatile u32*)(peripheral_reg_addr + lock_index<< 4))
{
if(!is_wait)
return false;
}
return true;
}
void lock_release()
{
*(volatile u32*)(peripheral_reg_addr + lock_index<< 4) = 1;
}该外设地址有读置1,写清零的效果。有个前提条件是:cpu同时在读该寄存器时,会通过硬件总线去仲裁,哪个核优先去执行,这样就保证了永远只有有个核会拿到锁。
2.3、软件代码实现
笔者介绍一个简单的AMP 版本的双核的自旋锁。
typedef struct spin_lock_struct
{
u32 lock[2];
u32 flag;
}spin_lock_t;
spin_lock_t mutex_lock_group_g[LOCK_MAX];
void lock_acquire(u8 cpu,u8 lock_index)
{
volatile spin_lock_t *spin_lock = &mutex_lock_group_g[lock_index];
spin_lock->lock[cpu] = 1;
spin_lock->flag = cpu;
while((cpu == spin_lock->flag) && (1 == spin_lock->lock[1-cpu]));
}
void lock_release(u8 cpu,u8 lock_index)
{
volatile spin_lock_t *spin_lock = &mutex_lock_group_g[lock_index];
spin_lock->lock[cpu] = 0;
}前提是全局变量是双核都可以访问,且没有cache缓存,写同一块内存时,硬件会进行总线仲裁,只有一个同时写。
index可供多把锁使用。
上面的拿锁核解锁正常有两种情况
- 一种是其中一个核已经拿完锁,另外一个去拿,此时通过判断对方的lock[cpu]值((1 == spin_lock->lock[1-cpu]))是否等于1,即可实现互斥作用,此时flag左右无效,因为随时就更改。
- 另外一种是两者同时进入该函数,在flag=1的情况下,由于双核同时访问,硬件决定互斥,只有一个可以写成功,另外一个要等下一个cycle才可以写,此时当前核接着运行,此时判断(cpu == spin_lock->flag),发现不满足,因为上面的另外一个核也写成功了,所以当前核不进行下一个判断了,则拿到锁,另外核去判断时,发现对方拿锁,则进入等待自旋。
通过一个flag可以解决同时进入的问题,没有该flag,则同时进入函数时,会导致双核都在等对方核释放,类似造成了死锁。
当然如果上面函数还可以新增一个参数,是否等待。
bool_t lock_acquire(u8 cpu,u8 lock_index,bool_t is_wait)
{
volatile spin_lock_t *spin_lock = &mutex_lock_group_g[lock_index];
spin_lock->lock[cpu] = 1;
spin_lock->flag = cpu;
while((cpu == spin_lock->flag) && (1 == spin_lock->lock[1-cpu]))
{
if(!is_wait)
return false;
}
return true;
}版权声明:
作者:ZhangYixi
链接:http://zyixi.xyz/arm%e5%ad%a6%e4%b9%a0%ef%bc%8820%ef%bc%89%e8%87%aa%e6%97%8b%e9%94%81%e7%9a%84%e7%90%86%e8%a7%a3%e4%b8%8e%e5%ae%9e%e7%8e%b0/
来源:一西站点
文章版权归作者所有,未经允许请勿转载。



共有 0 条评论