
ARM学习(10) 运行占据内存统计
笔者在群里看到有一个人问问题,说是要统计算法所占的内存数据。
1、背景介绍
开局先来张几张图吧,显示一下对话内容 看看大家的理解。
暂且命名问题是 小明提出,回答者有A、B、C




以上就是本篇文章的全部内容,让我们下次再讨论。
。。。。。。
2、各抒己见
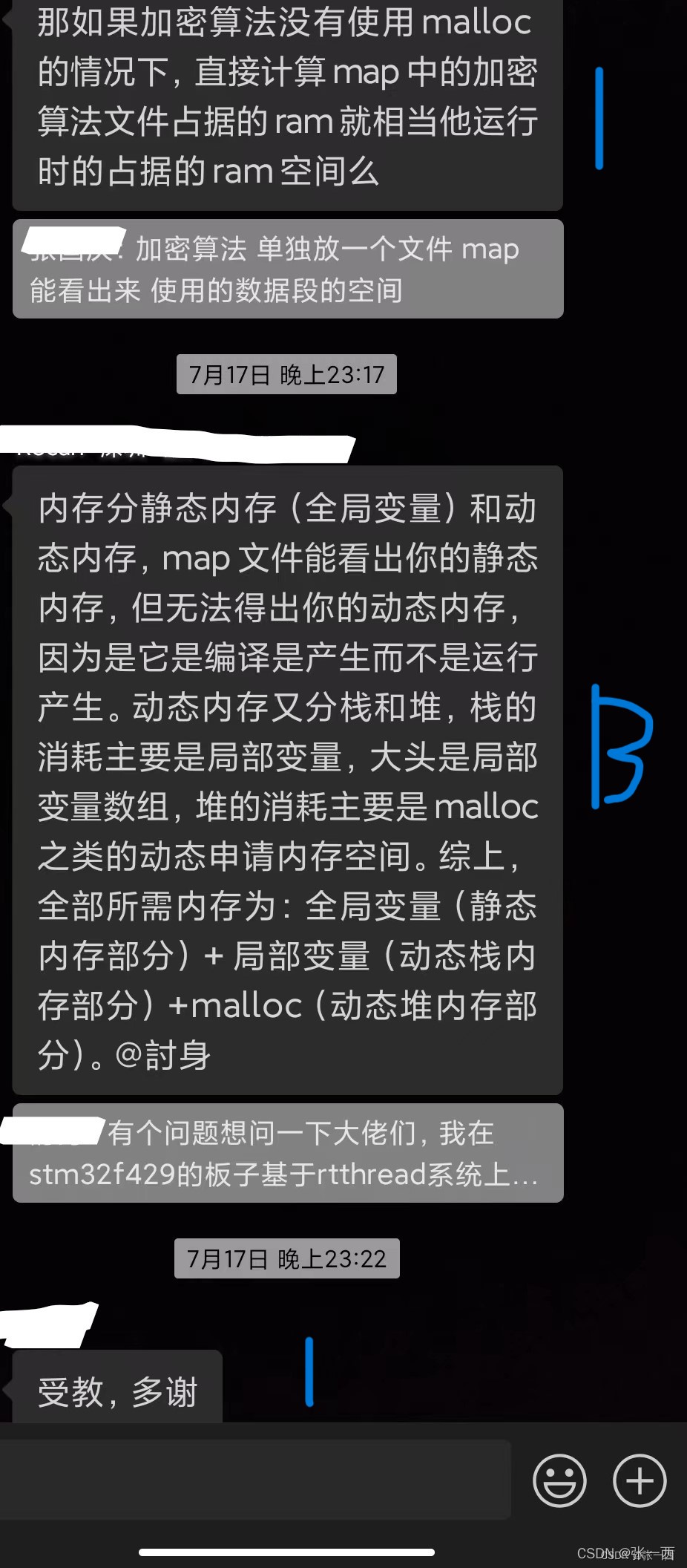
- 小明说:想要计算 一段算法在所占用的内存
- A(笔者):
- 建议看map文件,map文件可以看到data 段 的一些占用size,以armcc 为例,以.o为单位,统一一个.o文件中的data段的size。
- 所以我建议他放在一个文件,可以看到这个算法中.o文件的data段的大小,即就是全局变量以及静态变量所占用的size。
- 如果有malloc的话,会另算。
- 栈空间这块的,我没有考虑,栈是循环利用的,不是光算法占用,但是实际也应该考虑,如果栈消耗太大,则也会存在问题。
- 听同学说,如果代码需要放在内存中执行,那么这部分Code也需要占内存。
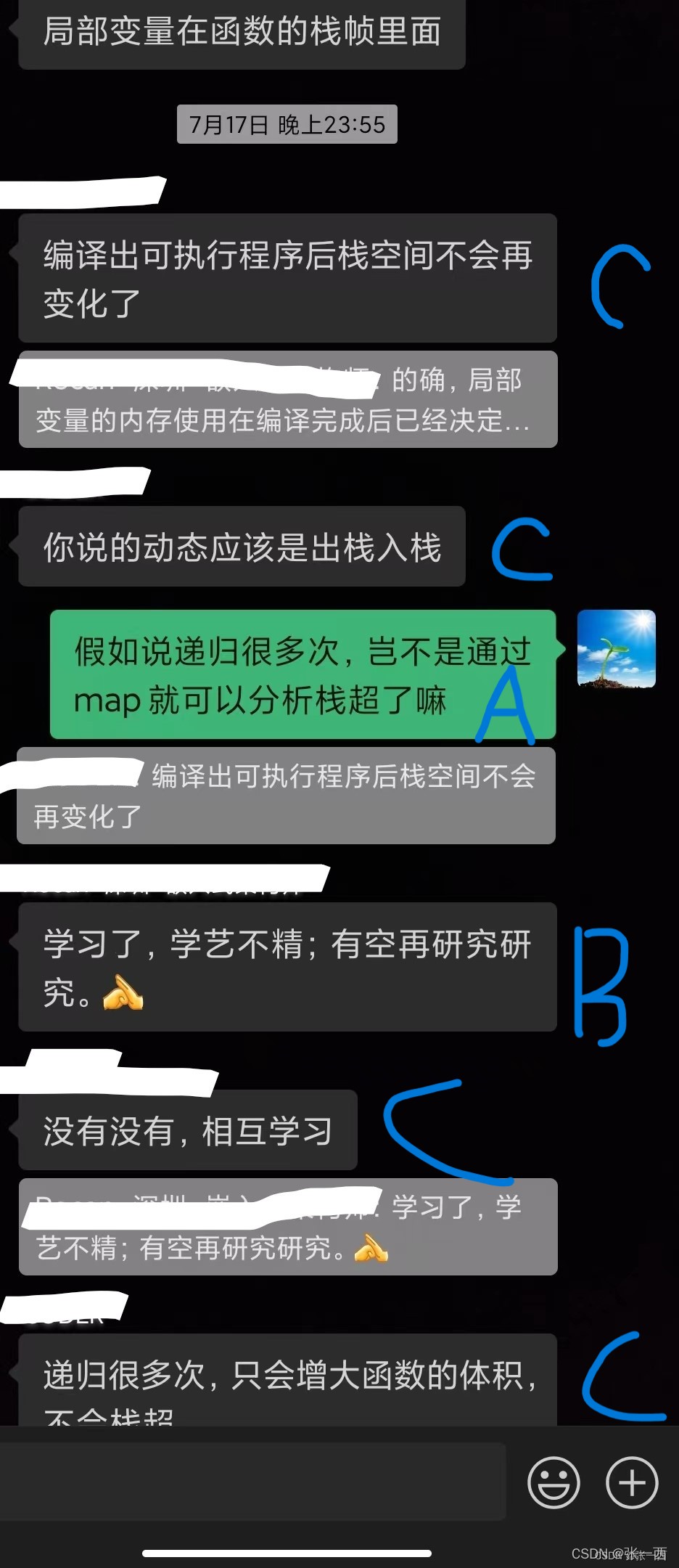
- B:认为:
- 全局所需内存=全局变量(静态内存部分)+ 局部变量(动态栈内存部分)+malloc(动态堆内存部分),
- map只能统计静态部分,不能统计动态部分,因为map是编译静态产生的,
- 动态内存分为栈和堆,栈体现在动态变化的,
- map文件中,局部变量是看不到,即便是偏移地址,而在汇编中是可以看到的,(栈中的偏移地址)
- C:认为:
- 局部变量是静态内存,编译时确定,map里面局部变量的地址是相对于函数的偏移。
- 函数大小包括局部变量大小
- 动态内存只有堆,没有栈,如果局部变量很大,则会看到函数的体积变大
- 编译出可执行程序后,栈空间就不会增大了。
- 递归多次,只会增大函数的体积,不会栈超,栈超了链接器会报错。
- map文件可以看出栈小,导致栈溢出的问题。
3、笔者分析
笔者来说说看法,经过试验得出的结果,以ARMCC、IAR以及GCC为例
3.1 ARMCC 分析
以一个例程来分析,led.c 最简单的
u32 LEDValue1 = 0XFFFF;
const u32 LEDValue2=0XFFFF;
u32 LEDValue3[4];
void LED_Init(void)
{
GPIO_InitTypeDef GPIO_InitStructure;
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_GPIOE, ENABLE);//使能GPIOF时钟
RCC_AHB1PeriphClockCmd(RCC_AHB1Periph_CRC, ENABLE);
//GPIOF9,F10初始化设置
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_11 | GPIO_Pin_12 |GPIO_Pin_13| GPIO_Pin_14;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_OUT;//普通输出模式
GPIO_InitStructure.GPIO_OType = GPIO_OType_PP;//推挽输出
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_100MHz;//100MHz
GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL;//上拉
GPIO_Init(GPIOE, &GPIO_InitStructure);//初始化
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_5;
GPIO_Init(GPIOD, &GPIO_InitStructure);//初始化
GPIO_Write(GPIOD,LEDValue1); //以下代码都是为了测试
GPIO_Write(GPIOE,LEDValue2);
LEDValue3[0]=0XFFFF;
GPIO_Write(GPIOE,LEDValue3[0]);
}
void LedRun()
{
GPIO_ResetBits(GPIOD,GPIO_Pin_5);
GPIO_SetBits(GPIOD,GPIO_Pin_5);
}
3.1.1 笔者A观点
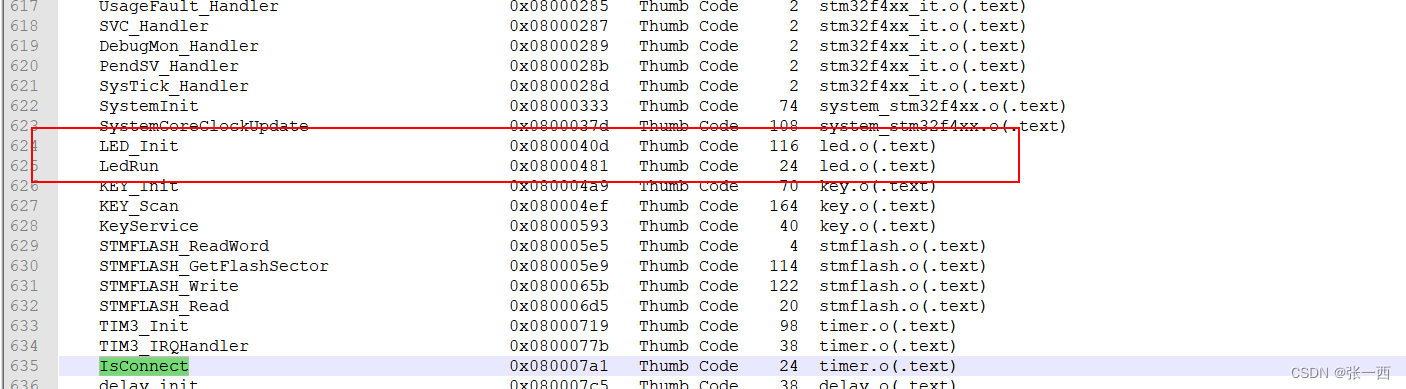
然后打开生成的map文件,可以看到具体编译好的信息,很方便分析单个.o文件所占用的size信息,比如该文件led.c

从上面Map信息里面看到Led.o的size情况:
- Code:156 Byte
- RW Data:4Byte
- ZI Data:16Byte
- RO Data:0Byte
所以如果算法单独使用了一个.o文件,在armcc下,很容易分析出数据的空间使用大小。但是栈的空间+堆的空间没有统计到,
堆是运行态的,静态编译出来的无法统计到,需要具体的情况具体分析,单独去看malloc这种,或者自己内存管理的空间申请。
至于栈的使用空间,编译阶段可能不知道,因为编译阶段不知道调用关系,而链接的时候则由链接器将多个.o文件组织起来,所以可以知道调用关系,
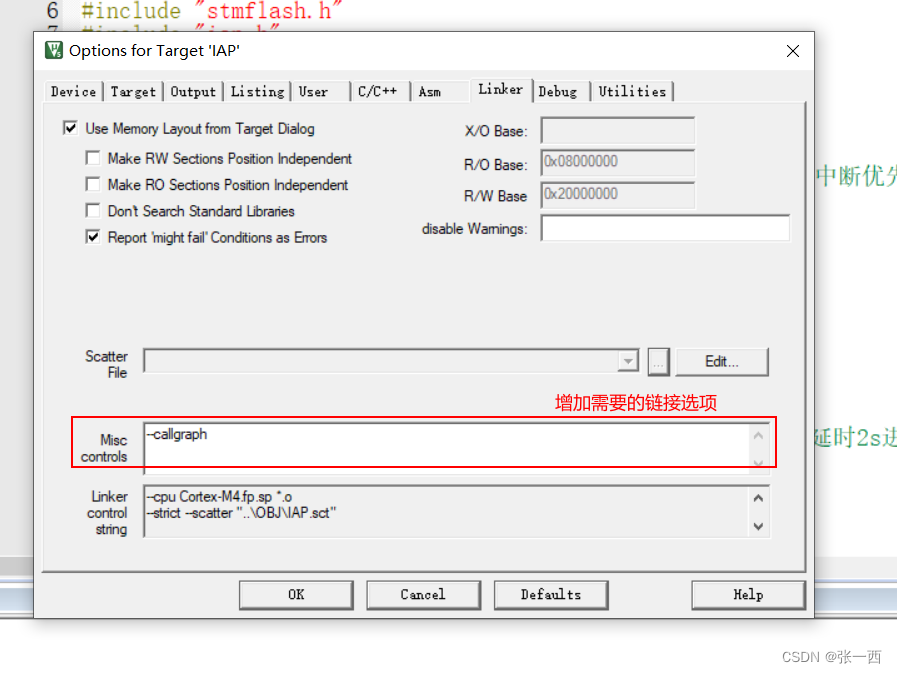
- 一个链接选项:--callgraph 就可以生成调用关系,
- 同时会分析出使用栈的情况。
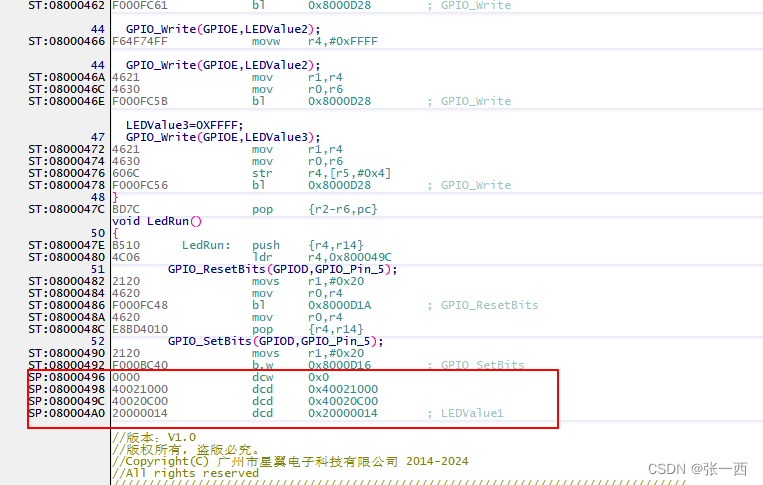
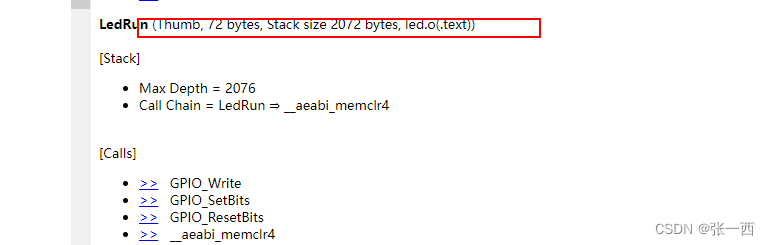
从下图可以看到 main->LED_Init->GPIO_Init ,LED_Init 初始化使用栈24Byte,
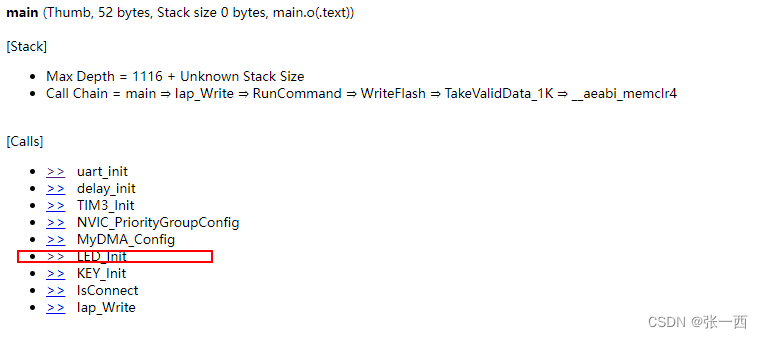

接着来分析一下,为啥LED_Init函数的栈使用了24Byte空间。
大家都知道,数据的运算以及函数的调用,都会用到寄存器,而用寄存器之前需要保存寄存器,所以栈主要是用来保存该函数用到的寄存器,来看一下汇编,很容易就明白了。
push的时候,都是4字节对齐的(寄存器都是32位的),所以总共push了6个寄存器,总共24Byte。
push {r2-r6,r14} 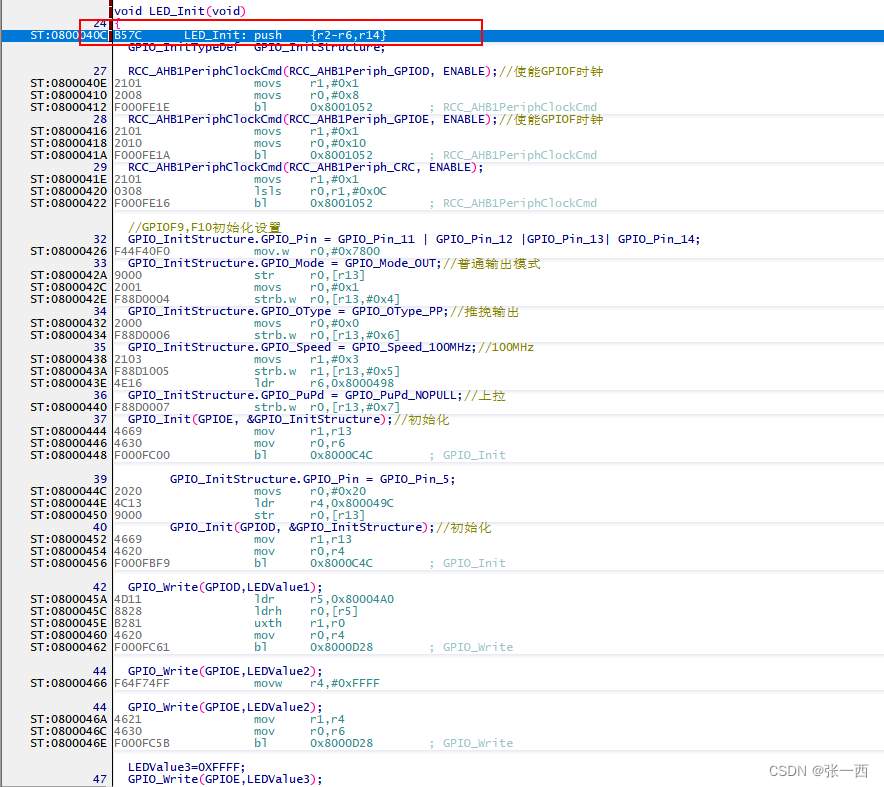
从上文可以看到LED.o共使用了156Byte,如何计算出来呢,就是将这个函数的指令编码都加起来就可以了,每个汇编指令会有数据,该数据就是汇编指令,就是机器码。
从map文件中来看,两个函数分别是116Byte + 24Byte,共140Byte,由上文可知,共156Byte,那么16Byte就是上文中的inc.data,就是Code中用到了一些数据,这些数据无法直接访问,需要开辟一块单元来存储这些数据地址,然后才可以加载。如下面第二张图所示,比如0x40021000,很明显这个就不是Code的地址或者RAM的地址,就是一个外设地址(GPIOE),根据STM32的手册可以得知(下面图三)。

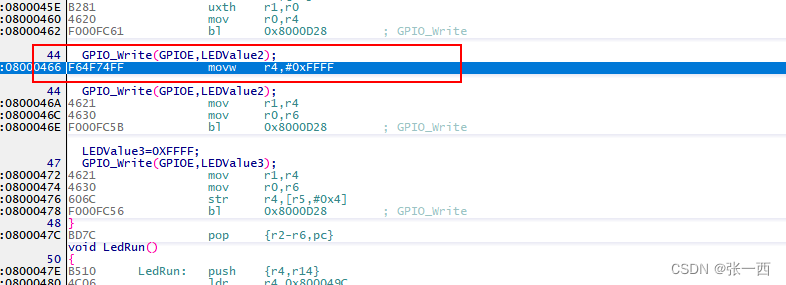
上文中RW Data 或者ZI Data 符合预期,但是RO Data 很奇怪是0,因为我们本身定义了一个const的类型的数据,但是统计竟然是0,
u32 LEDValue1 = 0XFFFF;
const u32 LEDValue2=0XFFFF;
u32 LEDValue3[4];这个需要从汇编入手,编译器也不傻,定义一个const 类型的数据,编译器会就生成一个RO data吗,不一定,比如本文这个,编译器直接将0xFFFF 编译到指令中,而不是从变量中加载数据,这个需要从汇编中看。
如何才能产生一个RO data呢?如果引用到变量的地址,那么肯定会产生一个RO data,因为需要分配变量地址。例如下文中这样。
u32 * data_p = (u32*)&LEDValue2;
*data_p = *data_p +1;
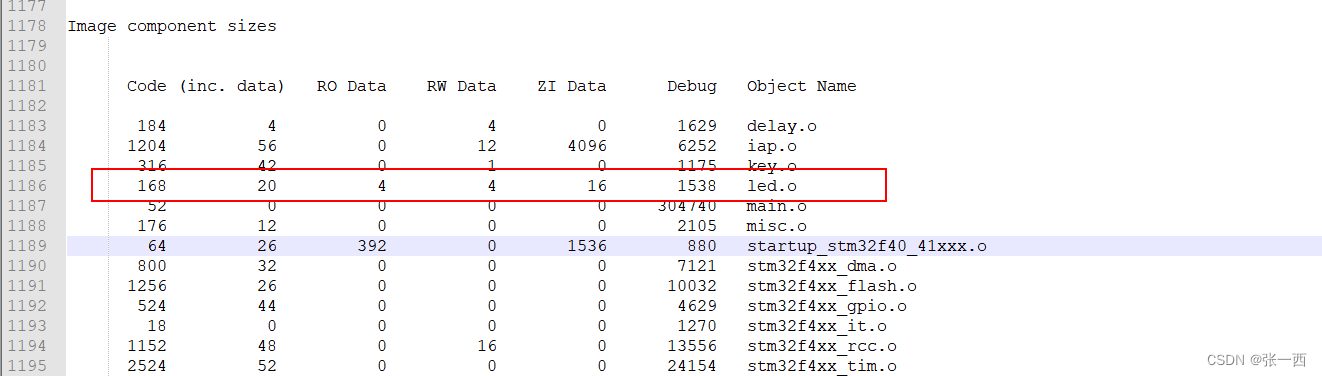
GPIO_Write(GPIOE,LEDValue2);然后分析map文件,可以看到RO data Size 为4,led.o中有了RO的变量以及地址,也可以看到ro data的地址不是在sram,而是在flash中(ROM)中,最后汇编也为const 变量申请了存储空间(LEDValue2)


3.1.2 B同学观点
对于B同学的观点,我基本 都是赞同的。
补充一下:就是所需要的内存,可能还需要加上Code所需要的空间(如果有这种场景的话,在内存中允许代码)
对于栈是动态的理解,我的想法也是栈是动态变化的
- 函数调用完成之后,栈就释放了,还可以重新使用,
- 和堆相似,但是和堆不同的是,栈动态变化过程是相对固定的,就是编译器编译好指令之后,每个函数的栈使用Size就确定了,不会在变化了。
- 唯一变化的可能就是一级一级的调用栈,这个链接器统计的有些情况可能不准,(统计最大size)
- 比如出现环形调用,统计出来的情况就不准,类似递归调用,准是有出口的,但是编译器不知道,就会统计出错。
- 还比如出现函数指针调用,编译器可能也无法统计出最大的调用栈size,无法统计出具体的调用关系。

map文件是看不到局部变量的,原因有两点,
- 栈是动态变化的,会覆盖掉,
- 而且如果多个函数调用,调用路径不一样,那么在栈中的偏移地址也不固定,所以说看不到的,
- 即便是汇编中,可以看到的是部分变量压栈,其他的可能还是在寄存器中使用,所以基本上地址无法确定。
map文件中看到的 全局变量 或者局部静态变量。
3.1.2 C同学观点
对于C同学的观点,很多我都有不同的意见,
- 对于第一条,map文件可以看到局部变量地址,这个我可以肯定是看不到的,除非进入函数那一刻,去获取地址,但是静态的map文件分析是看不到的。而且变量和代码是分开存放的,及时能看到,也不在同一个区域,怎么可能是函数地址的偏移呢???
- 对于第二条,函数的大小,我认为不包括局部变量的大小,局部变量的使用在栈中(寄存器),而栈的使用体现在sp的变化,也就是指令上面,从map文件中也可以看到LED_Run这个函数的大小是24Byte,在汇编中统计一下指令的大小(左边圈住的),恰好也是24Byte。

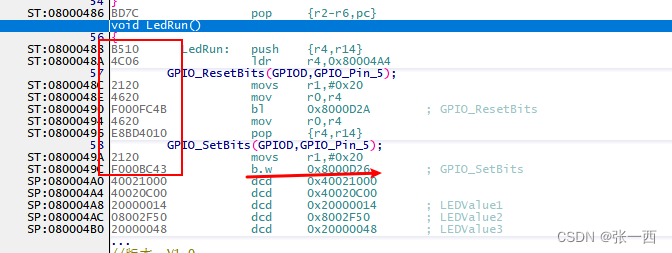
上面那个LedRun函数可能没有局部变量,那我们来加一个局部变量来看看,例如下面的代码,如果包括局部变量,那么函数的size一定会超过100,毕竟还有指令的size,实际编出来 的map文件分析,看到函数大小为64,分析汇编代码,指令数也是64,可以得出结论,函数的大小是不包括局部变量的。
void LedRun()
{
u16 LEDData[100]={123};
u8 i=0;
for(i=0;i<100;i++)
GPIO_Write(GPIOE,LEDData[i]); //测试,可能没意义
GPIO_ResetBits(GPIOD,GPIO_Pin_5);
GPIO_SetBits(GPIOD,GPIO_Pin_5);
}
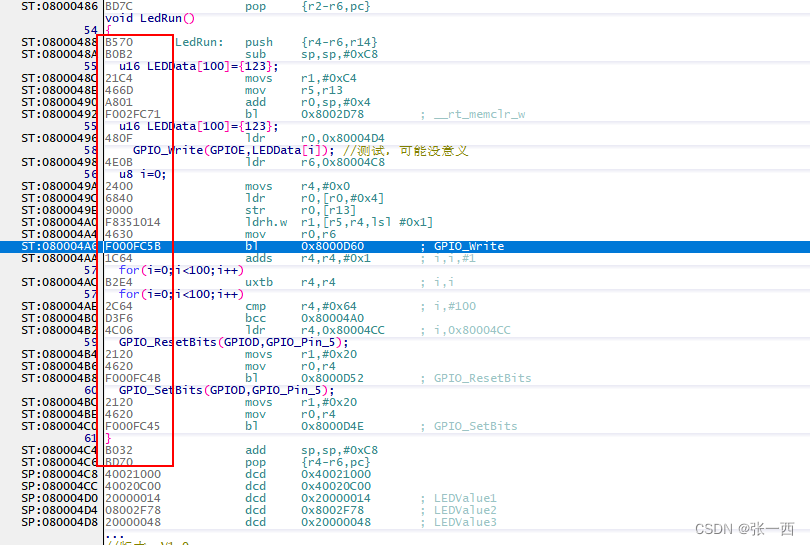
o文件的大小 包括了 code、data(RO RW ZI)的大小,也没包括局部变量的大小。
但是函数本身使用的局部变量空间是可以统计出来的,刚刚也看到了,通过链接器生成的信息。
216 = (1002)+ Push(44 寄存器r4 r5 r6 r14)

- 对于第三条,如第二条所述
- 第四条,程序编译好,栈空间的情况就不会变化了,这个也不是一定,比如有那种bank机制(下次介绍),由于Flash空间的限制,一些不常用的程序存放在nand里面或者其他spi nor flash里面,等用到的时候再加载,这样栈的空间使用也会相对的动态增加,当然这属于一种特殊情况。
- 第五条,栈超了会报链接错误,这个不会的,链接器存在环这种情况的时候,统计出来的栈使用是不准的,所以没法报错误,如果栈溢出了,可能会将其他空间踩了,引入其他bug。
举例说明,本程序的栈空间是0x400,还是刚刚的程序,同样可以编译过,没有报任何错误,还统计出来栈的使用情况(2064> 0x400(1024))。
void LedRun()
{
u16 LEDData[0x400]={123};
u16 i=0;
for(i=0;i<0x400;i++)
GPIO_Write(GPIOE,LEDData[i]); //测试,可能没意义
GPIO_ResetBits(GPIOD,GPIO_Pin_5);
GPIO_SetBits(GPIOD,GPIO_Pin_5);
}
- 第六条,map文件会分析栈的情况,好像也没有,至少对于armcc 编译器来说,没有统计栈的使用情况,而是在一个链接选项中 会专门生成栈的调用关系,以及所使用的栈情况。
以上就是笔者分析的一些情况,有不同分意见可以分享评论。后面简单以IAR以及arm-gcc 分析,看看是否有所不同。
附录:


版权声明:
作者:ZhangYixi
链接:http://zyixi.xyz/arm%e5%ad%a6%e4%b9%a0%ef%bc%8810%ef%bc%89-%e8%bf%90%e8%a1%8c%e5%8d%a0%e6%8d%ae%e5%86%85%e5%ad%98%e7%bb%9f%e8%ae%a1/
来源:一西站点
文章版权归作者所有,未经允许请勿转载。



共有 0 条评论