
ARM学习(9) arm 编译器了解学习(armcc/armclang)
笔者来聊聊编译器的用法
arm编译器学习
首先来了解一下编译器,其通常分为三个部分:前端+优化器+后端。
- 前端:词法、语法和语义分析,将源代码转化为抽象语法树,生成中间代码
- 优化器:对得到的中间代码进行优化,使得代码更加高效,
- 后端:将优化的代码转化为针对各自平台的机器代码。
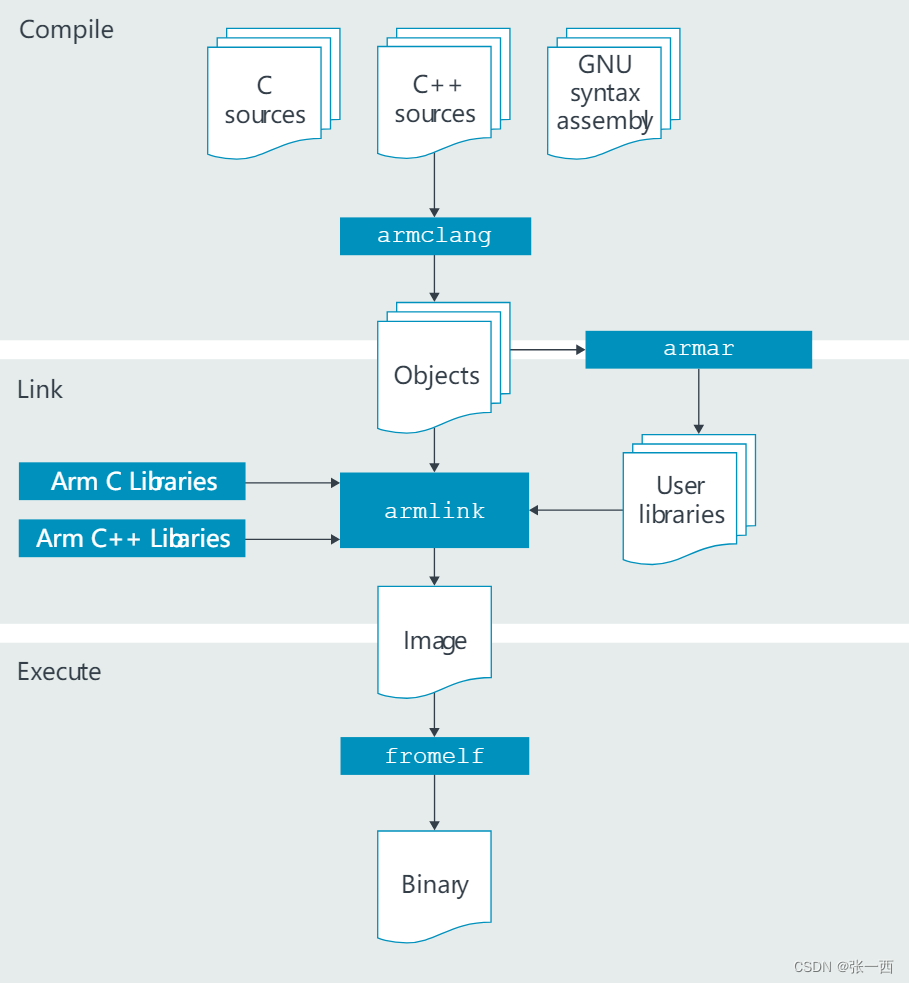
再通俗地说编译器的工作就是:源代码->预处理->编译->目标代码->链接->可执行程序。
再来简单看看一些编译器的历史,GCC、LLVM以及Clang等,以及文章介绍的armcc 以及armclang。
- GCC (GNU Compiler Collection)是GNU开发的编译器,许可证为GPL的自由软件;
- GCC 原来只能处理C,现在可以处理C++、Pascal、Object-C、Java等。
- 苹果公司之前一直使用GCC作为编译器,但是GCC对Objective-C支持一直不怎么好,好多新特性没有增加,所以苹果公司开始寻求编译器的替代品。
- 这个时候LLVM就出现了,是Chris Lattner在硕士和博士时提出和形成的编译器,不过其是采用GCC的前端进行语义分析,然后LLVM做优化和生成目标代码,可以叫做LLVM-GCC。
- 后来苹果公司直接计划绕开GCC,于是招募了Chris Lattner 博士开发编译器,Clang就这样诞生了,其基于LLVM开发的C/C++/Obj-C编译器,实际上其是一个编译器前端,来取代GCC或者超越GCC
- armcc 是arm 公司开发的一款编译器,集成在KEIL以及ARM DS IDE里面,于5.06版本后停滞(AC5),不继续维护,其前端基于 Edison Design Group 。
- armclang 集成于armcc,基于新的架构 clang 和LLVM,作为arm 的第六代编译器,AC6,成为今后主推的编译器。
armcc 编译器
arm 公司 开发的一款编译器,在2005年收购 KEIL 公司后,这块编译器就集成在KEIL IDE里面,以及自家开发的ARM DS5,编译器以及IDE相关的文档可以去ARM 公司的官网下载。
下载的文档主要分几个部分:armcc 编译器、armasm 汇编器、armlink 链接器、armar 打包以及fromelf bin文件。
1、armcc
armcc 编译器 主要是编译.c/.cpp源文件文件,生成目标文件,通过各种编译选项 command-line来支持各种特性。接着来罗列几个常见的编译选项。
一般的arm cc的编译器的编译器的语法如下:
armcc [options] [source]
举例如下:
armcc -I ../common/ -I ../driver -g --apcs=interwork --cpu=Cortex-R5 -c ../common/led.c -o ../out/led.o- -c/-C/-o/-D
-c 代表 只是编译,不进入链接步骤,
-C 保留预处理的输出,然后-E 可以指定预处理输出到某个指定文件。armcc -c -C -E -I ../common/ -I ../driver -g --apcs=interwork --cpu=Cortex-R5 ../common/led.c -o ../out/led.i这样之后,可以看到预处理的结果,比如宏替换后的结果,方便分析问题。
-o 指定输出的文件名称

-D 定义宏名称,例如:-DLOG -DUART=1 -U 移除已经定义的宏名称
#define LOG
#define UART 1在编译器命令行指定上面的宏,相当于在程序里面定义上述代码的定义
- "-I":指定include的目录 ,如果路径没指定,编译阶段就会报错,找不到相关的文件,相比大家都见过这个错误吧。
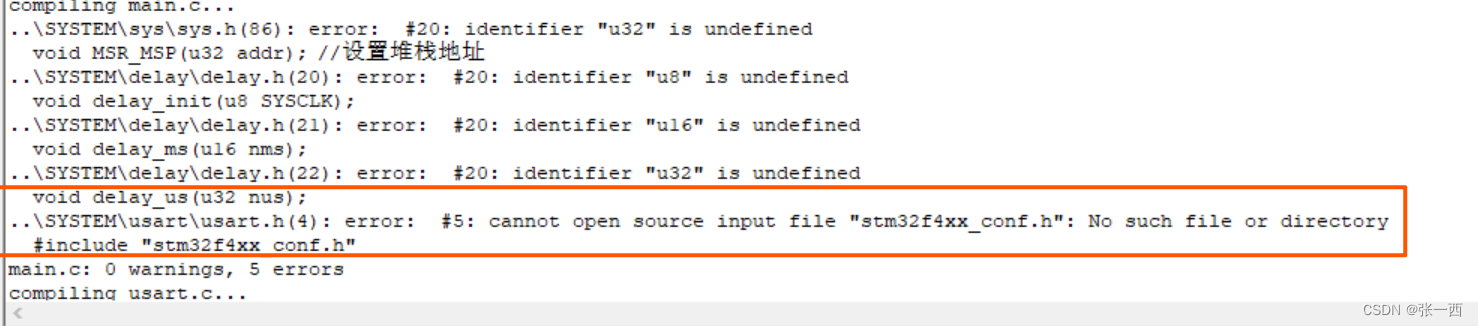
- --c99 --c90 指的的是C语言的语法版本

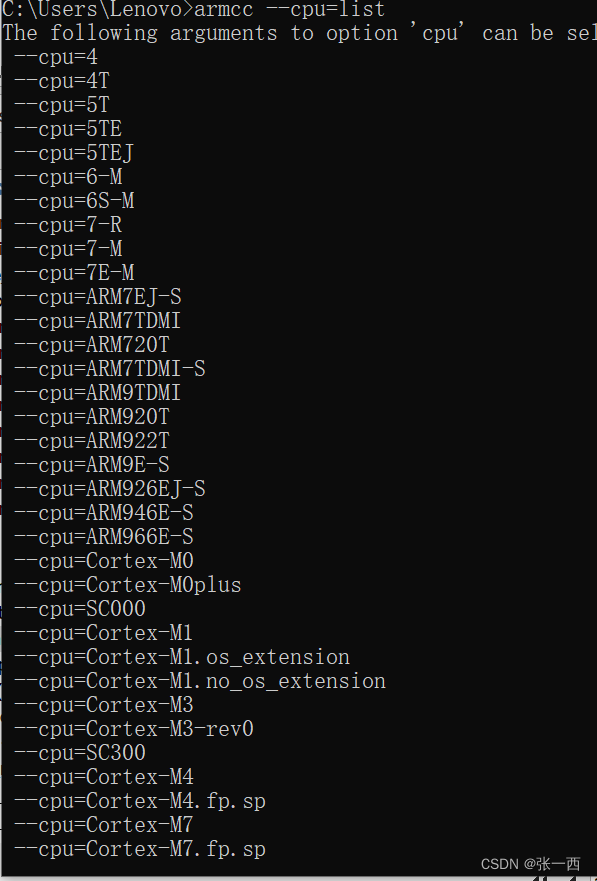
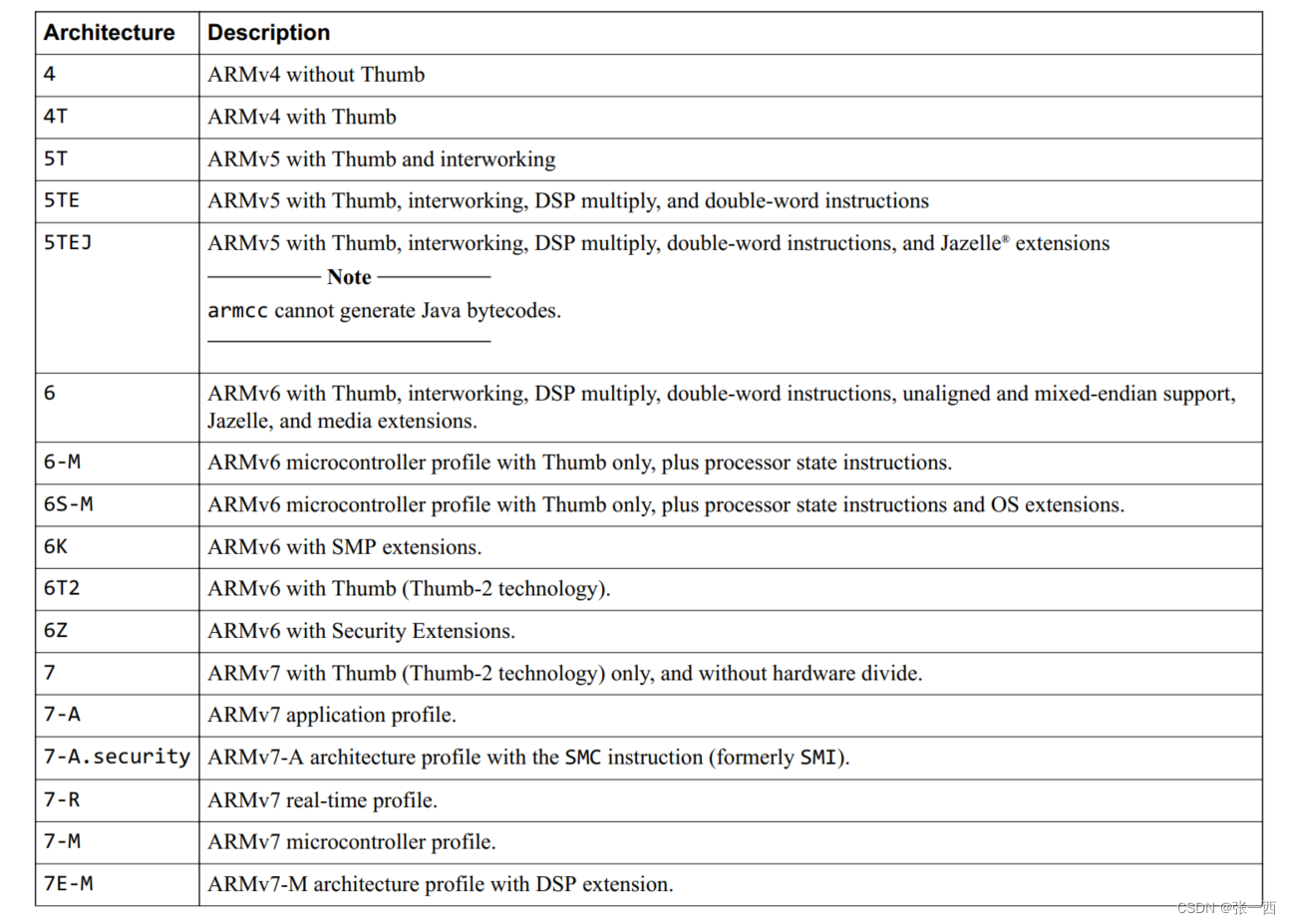
- --cpu=name 比如 --cpu=Cortex-R5
- -M/--md 这两个是用来为每个源文件产生编译依赖,--md 生成.d文件,表示这个目标文件所依赖的头文件。这个在增量编译非常有用,再找到依赖关系后,更新依赖,则可以只编译修改的文件以及依赖的文件。

armcc -c -M -I ..\SYSTEM\sys -I ... sys.c --no_depend_single_line --md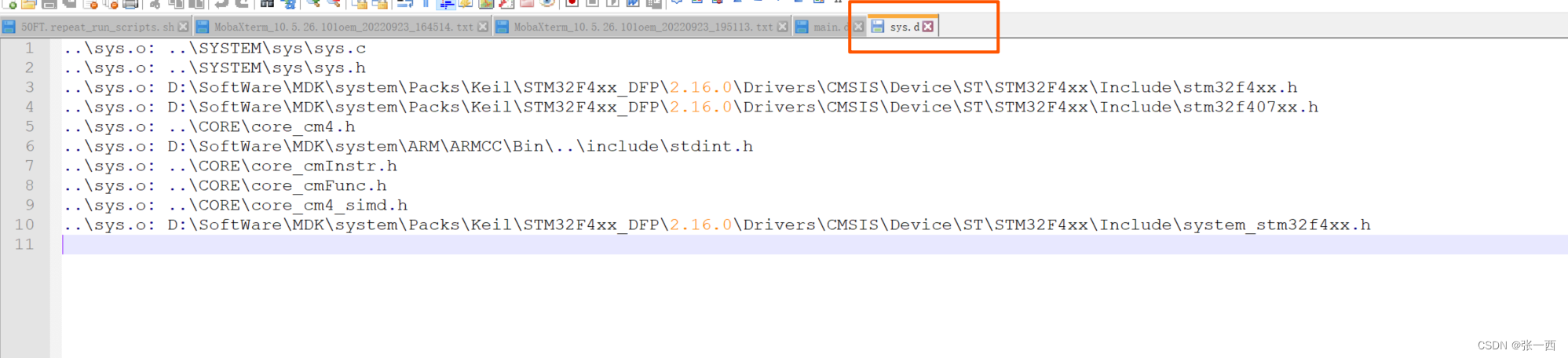
- --diag_error/--diag_suppress/--diag_warning 对编译的警告以及错误进行处理,比如屏蔽某个编译警告/错误
--diag_error=warning 将err的编译消息视为warning, --diag_suppress=3017,1256,1148 将编译消息 编码为 3017,1256,1148的诊断消息屏蔽 --diag_warning=1234,5678 屏蔽编码为 1234,5678的warning的诊断消息 --diag_warning=error 将warning视为error
例如下面的20、223 这种编码序号。

- --feedback=filename 编译反馈,主要是用来去除没有用到的代码 (数据以及code),需要与链接的选项一起使用,通常需要编译两次。
--feedback=unused_section.txt 编译器阶段把没用到的代码和code单独放在一个section,方便链接阶段去除,链接阶段,生成不用的section区 --feedback=image_none 忽略链接阶段的链接脚本,忽略代码布局,则不会生成axf文件 --remove 去除不用的section --keep memory_alyout.o\(rw\) 可以设置memory_out.o中的rw段不删除 通过feedback,空间从950k -> 800k (双core的bin 所需空间) - --inline/--forceinline 前者会对函数是否内敛进行考虑,后者强制将所有函数进行内敛,要对单个函数进行内敛,可以考虑对函数进行修饰,__forceinline。
- 需要注意的是,并不是所有的函数都可以内联,比如递归函数。

- --littleend/--bigend 数据大小端设置,
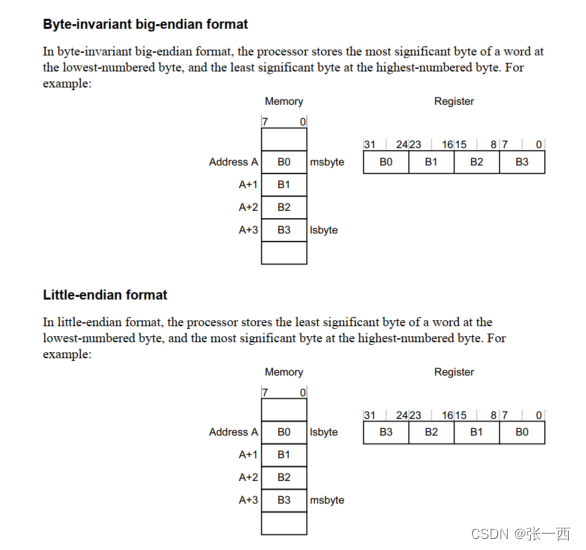
- -O0/O1/O2/O3/Otime/Ospace 编译优化选项
- O0 最小优化。关闭大多数优化。
启用调试时,此选项提供最佳调试视图,因为生成代码的结构直接对应于源代码。所有干扰调试视图的优化都被禁用。- 可以在任何可到达的点设置断点,包括死代码(程序执行不到的地方 或者没有受调用的地方)。
- 变量的值在其范围内的任何地方都可用,但它所在的位置除外未初始化。
- Backtrace 提供了读取源代码时预期的函数调用栈关系。
- 虽然 -O0 生成的调试视图与源代码最接近,但用户可能更喜欢 -O1 生成的调试视图,因为在不改变基本结构的情况下,提高了代码的质量
- 死代码包括对程序结果没有影响的代码,例如对从未使用过的局部变量的赋值。无法访问的代码是专门的代码无法通过任何控制流路径访问,例如紧跟在返回之后的代码。
- 即使声明了内联函数,也不会内联,会当函数(symbol)处理,(gcc编译器也类似)
- O1受限优化。编译器只执行可以描述为调试信息的优化。
删除未使用的内联函数和未使用的静态函数。关掉严重降低调试视图的优化。如果与 --debug 一起使用,此选项会给出总体上令人满意的调试视图且具有良好的代码密度。
调试视图与 –O0 的区别在于:- 不能在死代码上设置断点。
- 变量的值在初始化后可能在其范围内不可用。例如,如果他们分配的位置已被重复使用。
- 没有影响的函数可能会被乱序调用,或者如果结果是不需要的。
- Backtrace 可能不准确,因为在栈的方面处理有变化,存在调用优化。
- 优化级别 –O1 在源代码和对象之间产生良好的对应关系代码,特别是当源代码不包含死代码时。
- 生成的代码可以是明显小于 –O0 处的代码,这可以简化目标代码的分析。
- 会将声明为inline的函数进行内联处理
- O2高度优化。
如果与 --debug 一起使用,调试视图可能不太令人满意,因为目标代码到源代码的映射并不总是清晰的。 编译器可能会执行调试信息无法描述的优化。
这是默认的优化级别。
调试视图与 –O1 的区别在于:- 源代码到目标代码的映射可能是多对一的,因为可能多个源代码位置映射到目标文件的一个点,更激进的指令优化。
- 允许指令调度跨越序列点。 这可能导致变量在特定点的报告值与期望的值不匹配。
- 编译器自动内联函数
-
O3最大优化。
启用调试后,此选项通常会提供较差的调试视图。 ARM 建议在较低的优化级别进行调试。
如果同时使用 -O3 和 -Otime,编译器会执行更积极的额外优化,例如:- 高级标量优化,包括循环展开。这可以给显着以较小的代码大小成本获得性能优势,但存在构建时间较长的风险。
- 更积极的内联和自动内联。
- 这些优化有效地重写了输入源代码,导致目标代码与源代码的最低对应和最差的调试视图。 --loop_optimization_level=option ,控制在 –O3 –Otime 执行的循环优化效果。循环优化的数量越高,源代码和目标代码之间的对应关系就越差。
- 使用 --vectorize 选项还降低了源代码和目标代码之间的对应关系。有关在源代码上执行的高级转换的更多信息,请访问–O3 –Otime 使用 --remarks 命令行选项。
- 因为优化会影响目标代码到源代码的映射,所以使用 -Ospace 和 -Otime 选择优化级别通常会影响调试视图。
- 如果需要简单的调试视图,选项 -O0 是最好的选择。 选择 -O0 通常会将 ELF 映像的大小增加 7% 到 15%。 要减小调试表的大小,请使用--remove_unneeded_entities 选项
- --split_sections
为每个源文件的函数创建一个section,方便在链接的时候去掉.o文件 中的不用的函数。
--attribute((section(...))) 可以修饰data 和 function,将其放到指定的section,而不是放到默认的section - --thumb
将该.c文件编译成 thumb指令,#pragma arm 编译成arm指令 #pragma thumb 编译成thumb指令 #pragam push 保存#pragma 状态 #pragma pop 弹出状态 与上面的可以一起使用 #pragma pack(n) 设置 n字节对齐,对于结构体来说。 - --use_frame_pointer
这个设置栈顶指针,每次进入函数后,会首先将栈顶压入栈,之后再做其他的寄存器压栈,这样的好处是backtrace的调用关系很容易找出来。详见[ARM学习(1) 寄存器的理解 ===》FP、SP、LR寄存器]
- -apcs=interwork 支持内部thumb与arm 指令相互切换,比如BLX,这个支持thumb指令的地方用处较多.
2、armasm
- 嵌入式汇编
- 函数形参列表可以使用变量,但是函数体必须要用寄存器,函数体都是汇编语言实现
- 需要汇编语言处理返回指令
__asm return-type function-name(parameter-list) { // ARM/Thumb assembly code instruction{;comment is optional} ... instruction } /*示例1*/ __asm int f(int i) { ADD r0, r0, #1 } /*示例2*/ #include <stdio.h> __asm void my_strcpy(const char *src, char *dst) { loop LDRB r2, [r0], #1 STRB r2, [r1], #1 CMP r2, #0 BNE loop BX lr } int main(void) { const char *a = "Hello world!"; char b[20]; my_strcpy (a, b); printf("Original string: '%s'\n", a); printf("Copied string: '%s'\n", b); return 0; }
-
内联汇编
- 同一行如果有多行指令,必须要有封号(;)
- 如果一个指令超出一行,需要增加反斜杠(\)
- 在多行格式中,允许在内联汇编语言块中的任何位置使用C和C++注释。但是注释不能嵌入到多条指令的行中。
- 在汇编语言中,逗号(,)用作分隔符,所以C表达式的逗号运算符必须用括号括起来来和它们进行区分
- 标签必须后跟冒号,:,如C和C++标签
- asm语句必须位于C++函数内部。asm语句可以在任何需要C++语句的地方使用
- 内联程序集代码中的寄存器名被视为C或C++变量。它们不一定与同名的物理寄存器有关。如果寄存器未声明为C或C++变量,编译器将生成警告
- 不得在内联程序集代码中保存和还原寄存器,编译器会执行此操作。此外,内联汇编程序不提供对物理寄存器的直接访问。然而,可以通过变量间接访问寄存器
- pc/lr/sp:current_pc,__current_sp, and return_address 来read
- 内联汇编中不要修改处理器模式或者协处理器的状态
int f(int x) { __asm { STMFD sp!, {r0} // save r0 - illegal: read before write ADD r0, x, 1 EOR x, r0, x LDMFD sp!, {r0} // restore r0 - not needed. } return x; } The function must be written as: int f(int x) { int r0; __asm { ADD r0, x, 1 EOR x, r0, x } return x; } int foo(int x, int y) { __asm { SUBS x,x,y BEQ end } return 1; end: return 0; }
- 汇编语言
待完善 - 汇编选项
- --cpu :CPU类型
- --apcs :arm与thumb指令混合调用与使用
- --depend :写出汇编文件的依赖关系到文件,make工具会使用该依赖关系去增量编译
汇编选项一般都比较少,只是编译启动文件会用到,例如STM32的等,都不多,选择对应的CPU以及架构,基本就可以。
--cpu Cortex-M3 -g --apcs=interwork --pd "__MICROLIB SETA 1"
-I D:\SoftWare\MDK\system\Packs\Keil\STM32F1xx_DFP\2.3.0\Device\Include
--pd "__UVISION_VERSION SETA 537" --pd "STM32F10X_HD SETA 1" --list ".\Listings\*.lst" --xref -o "*.o" --depend "*.d" 3、 armlink
- Image结构与视图
- 链接器优化
- 链接符号管理
- 链接脚本语法
- 链接选项
4、 armar
5、fromelf
armclang 编译器
armclang 相较于 armcc的优势
参考
版权声明:
作者:ZhangYixi
链接:http://zyixi.xyz/arm%e5%ad%a6%e4%b9%a0%ef%bc%889%ef%bc%89-arm-%e7%bc%96%e8%af%91%e5%99%a8%e4%ba%86%e8%a7%a3%e5%ad%a6%e4%b9%a0%ef%bc%88armcc-armclang%ef%bc%89/
来源:一西站点
文章版权归作者所有,未经允许请勿转载。



共有 0 条评论